Ucto tokenizes text files: it separates words from punctuation, and splits sentences. It offers several other basic preprocessing steps such as changing case that you can all use to make your text suited for further processing such as indexing, part-of-speech tagging, or machine translation.
Ucto comes with tokenisation rules for several languages and can be easily extended to suit other languages. It has been incorporated for tokenizing Dutch text in Frog, our Dutch morpho-syntactic processor.
Features
- Comes with tokenization rules for English, Dutch, French, Italian, and Swedish; easily extendible to other languages.
- Recognizes dates, times, units, currencies, abbreviations.
- Recognizes paired quote spans, sentences, and paragraphs.
- Produces UTF8 encoding and NFC output normalization, optionally accepts other encodings as input.
- Optional conversion to all lowercase or uppercase.
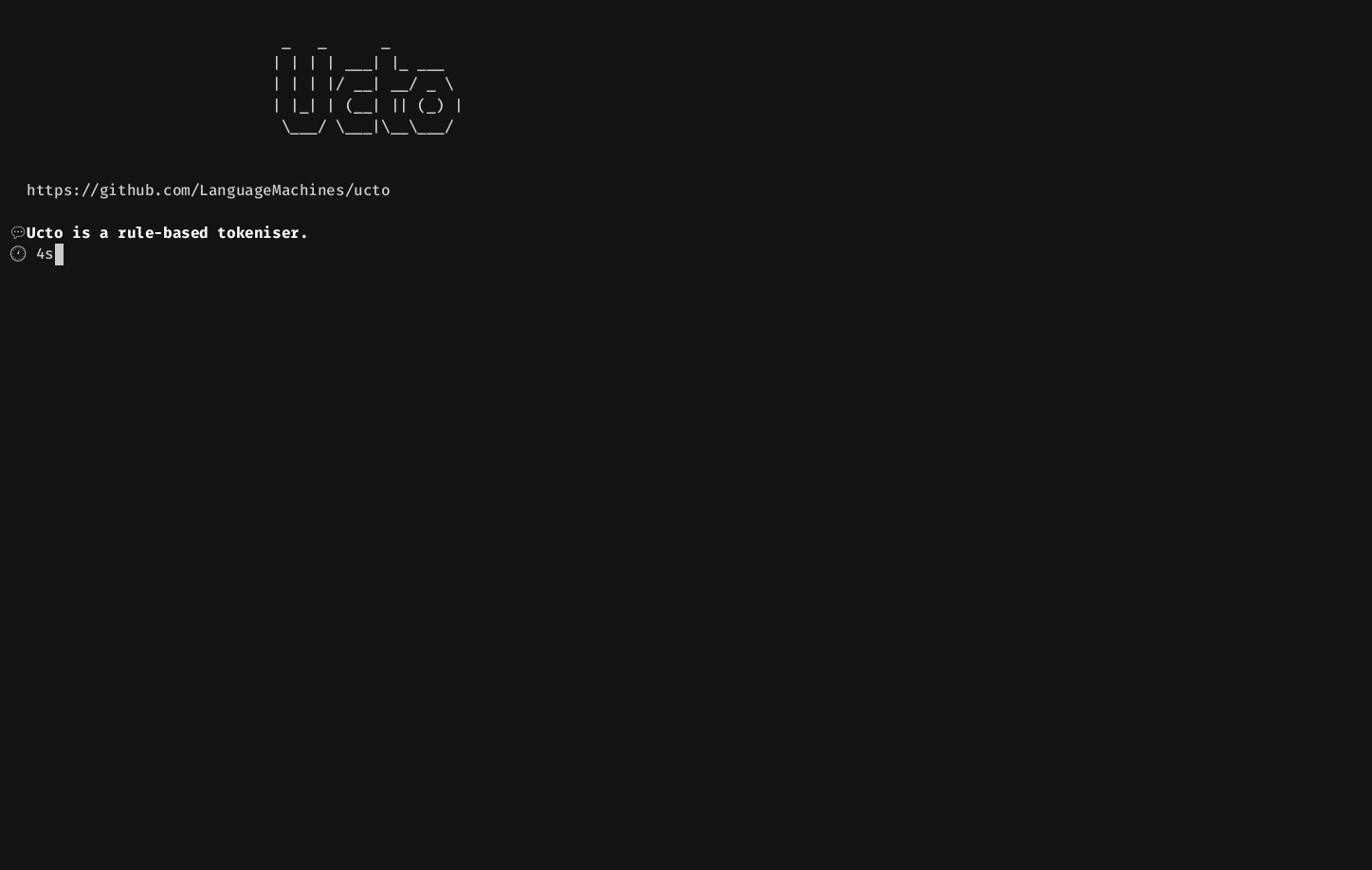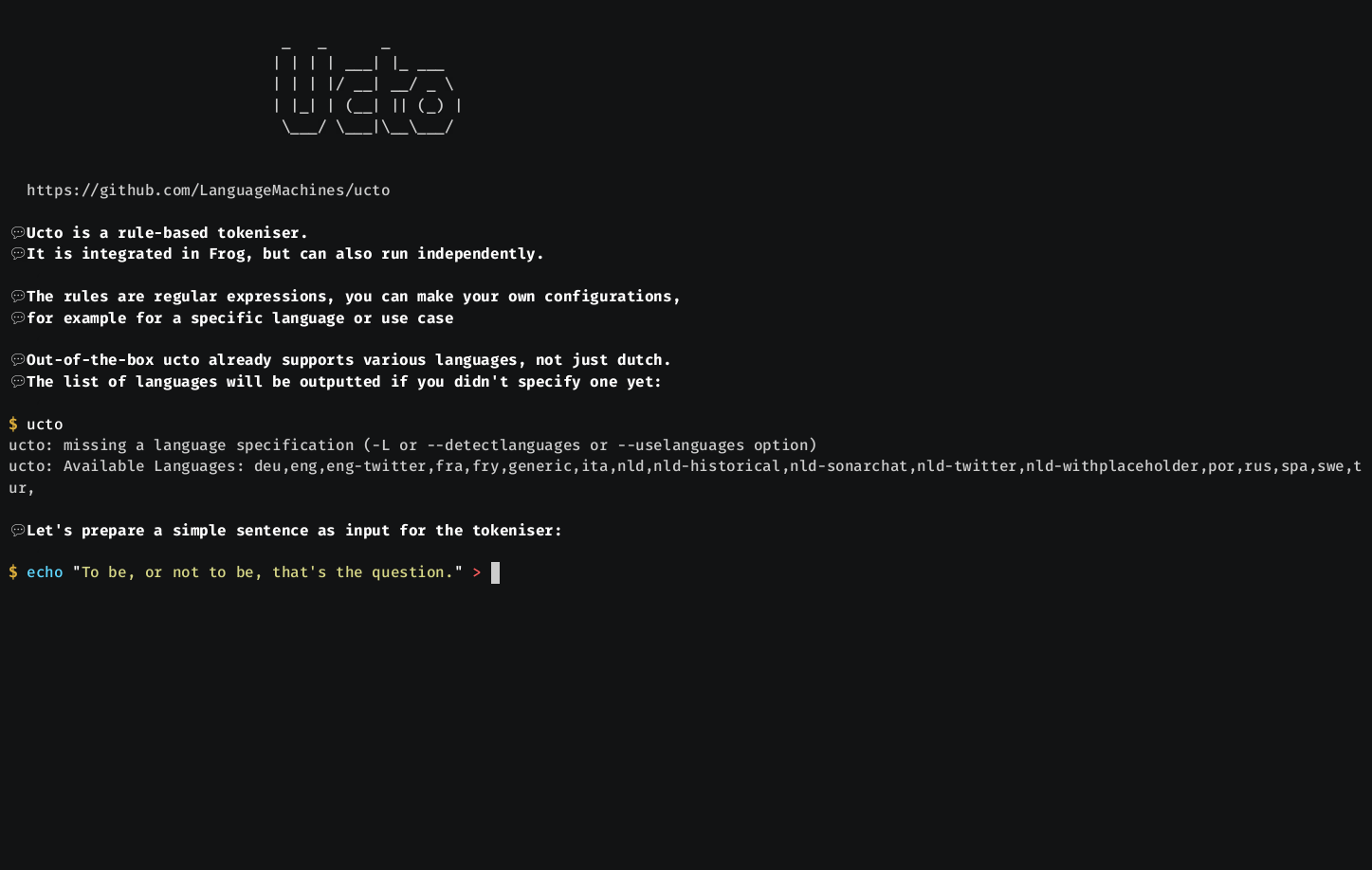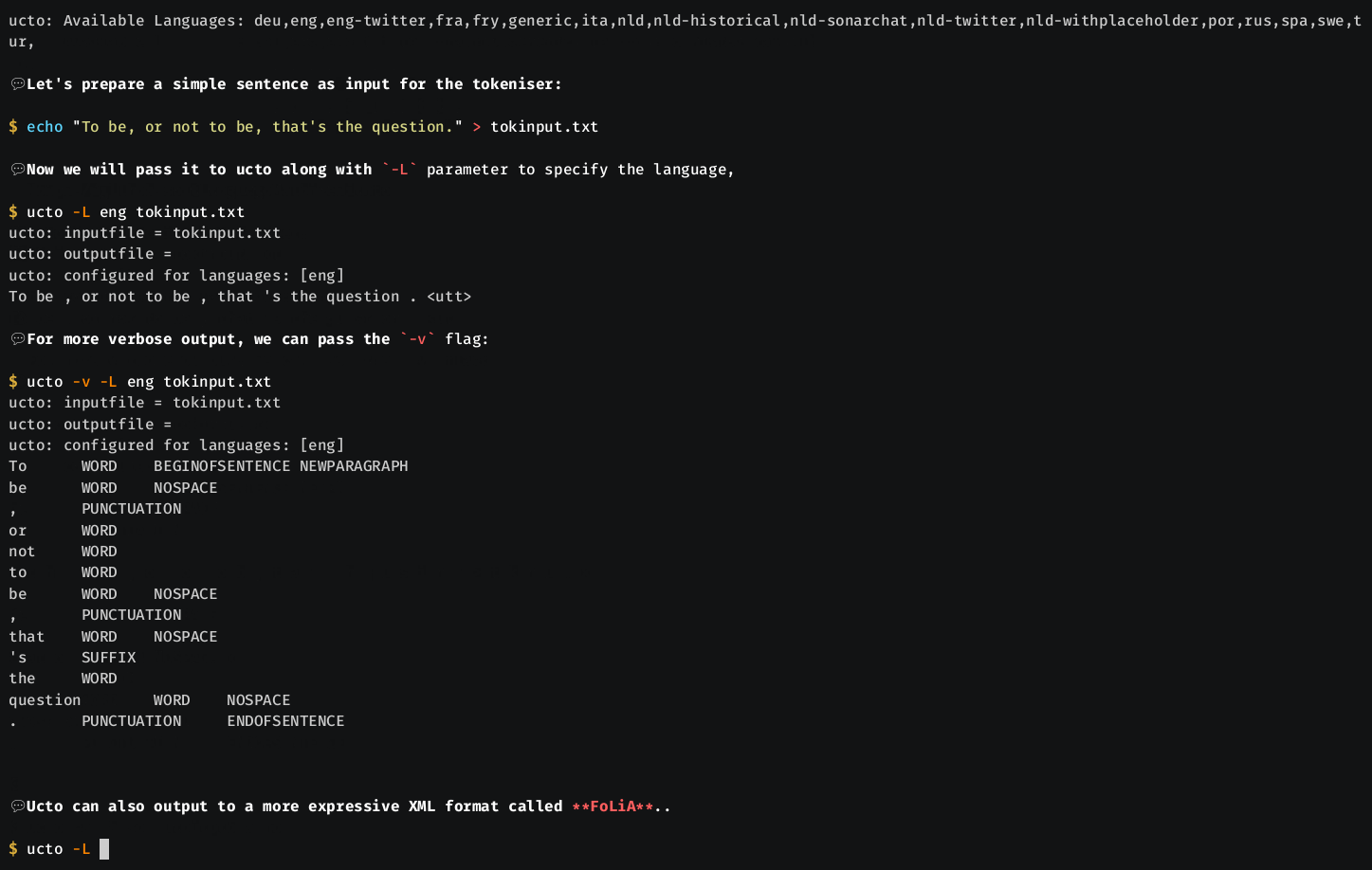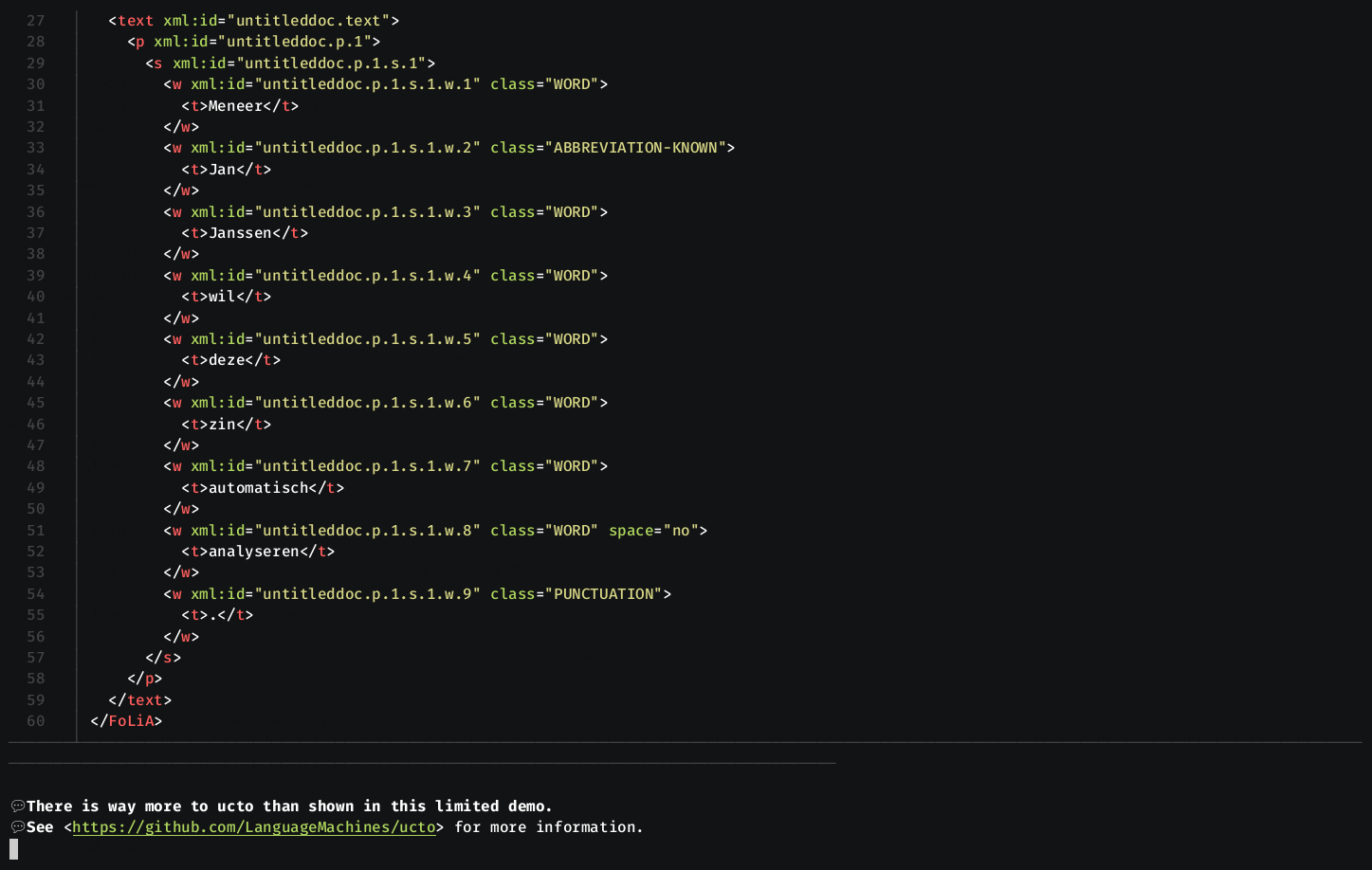
- Supports FoLiA XML
Ucto was written by Maarten van Gompel and Ko van der Sloot. Work on Ucto was funded by NWO, the Netherlands Organisation for Scientific Research, under the Implicit Linguistics project, the CLARIN-NL project, and the CLARIAH project.
The development and improvement of Ucto also relies on your bug reports, suggestions, and comments. Use the github issue tracker or mail lamasoftware (at) science.ru.nl.
Download & Installation
Ucto is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation.
To download and install Ucto:
- First check if there are up-to-date packages included in your distribution's package manager. There are packages for Alpine Linux, Arch Linux (AUR), macOS (homebrew), Debian, FreeBSD and Ubuntu.
- If you're only interested in the Ucto Python binding, then a simple pip install python-ucto suffices.
- If not, we recommend you use our docker container via docker pull proycon/ucto. It includes ucto and all necessary dependencies
- Alternatively, you can always download, compile and install ucto manually, as shown next.
Manual installation
To compile these manually consult the included INSTALL documents, you will need current versions of the following dependencies of our software:
As well as the following 3rd party dependencies:
Documentation
The ucto documentation can be found here.Python binding
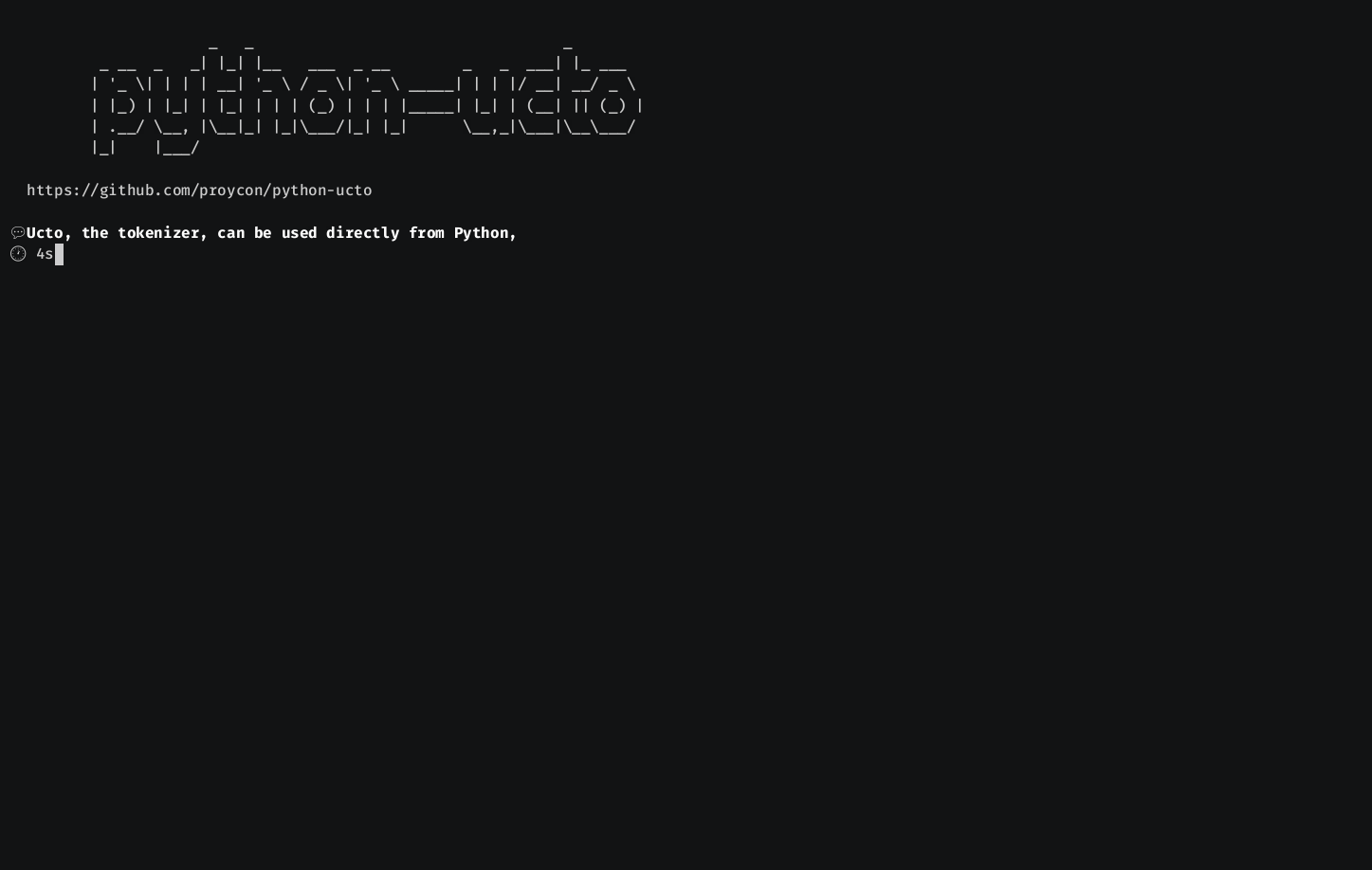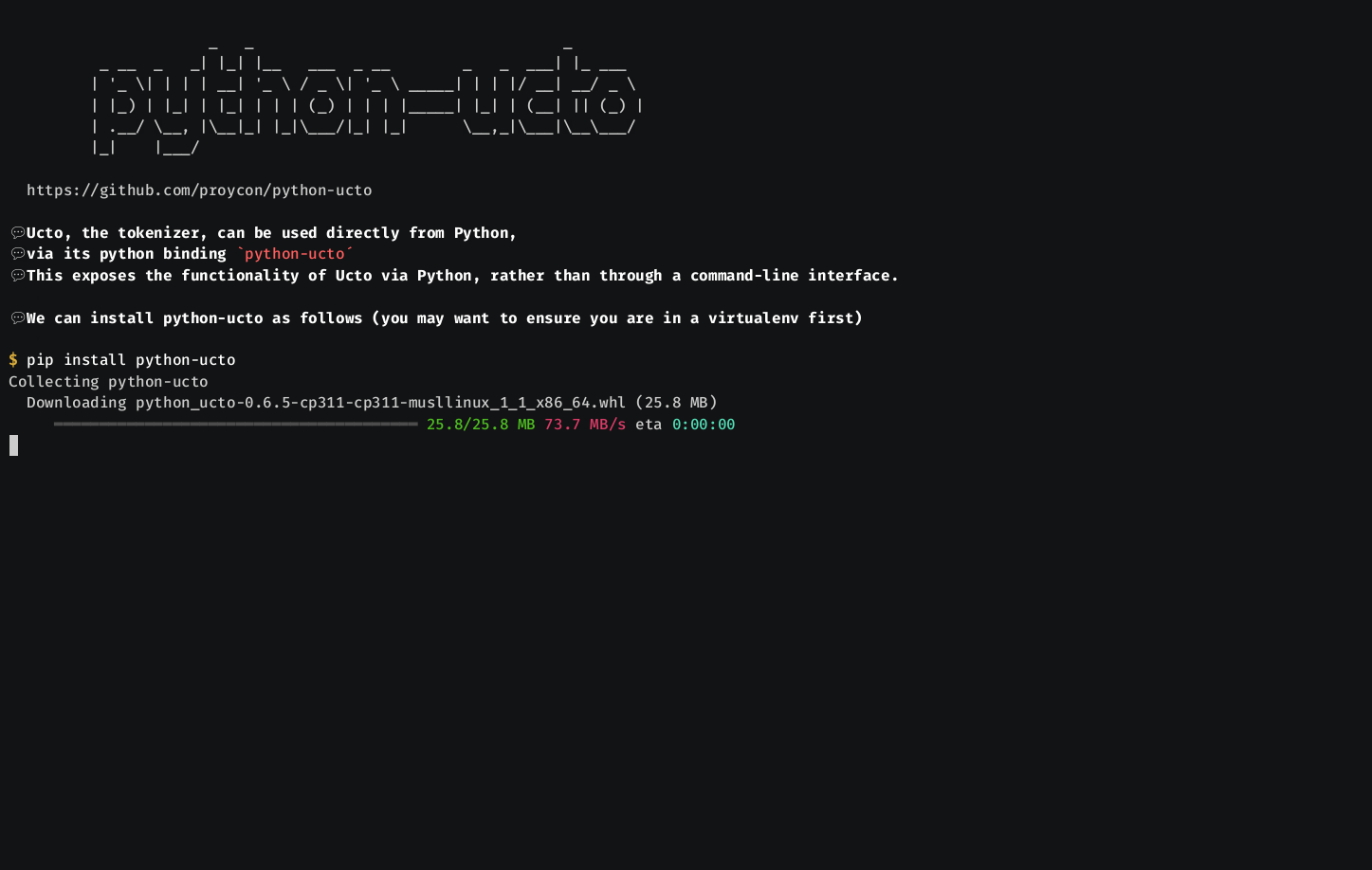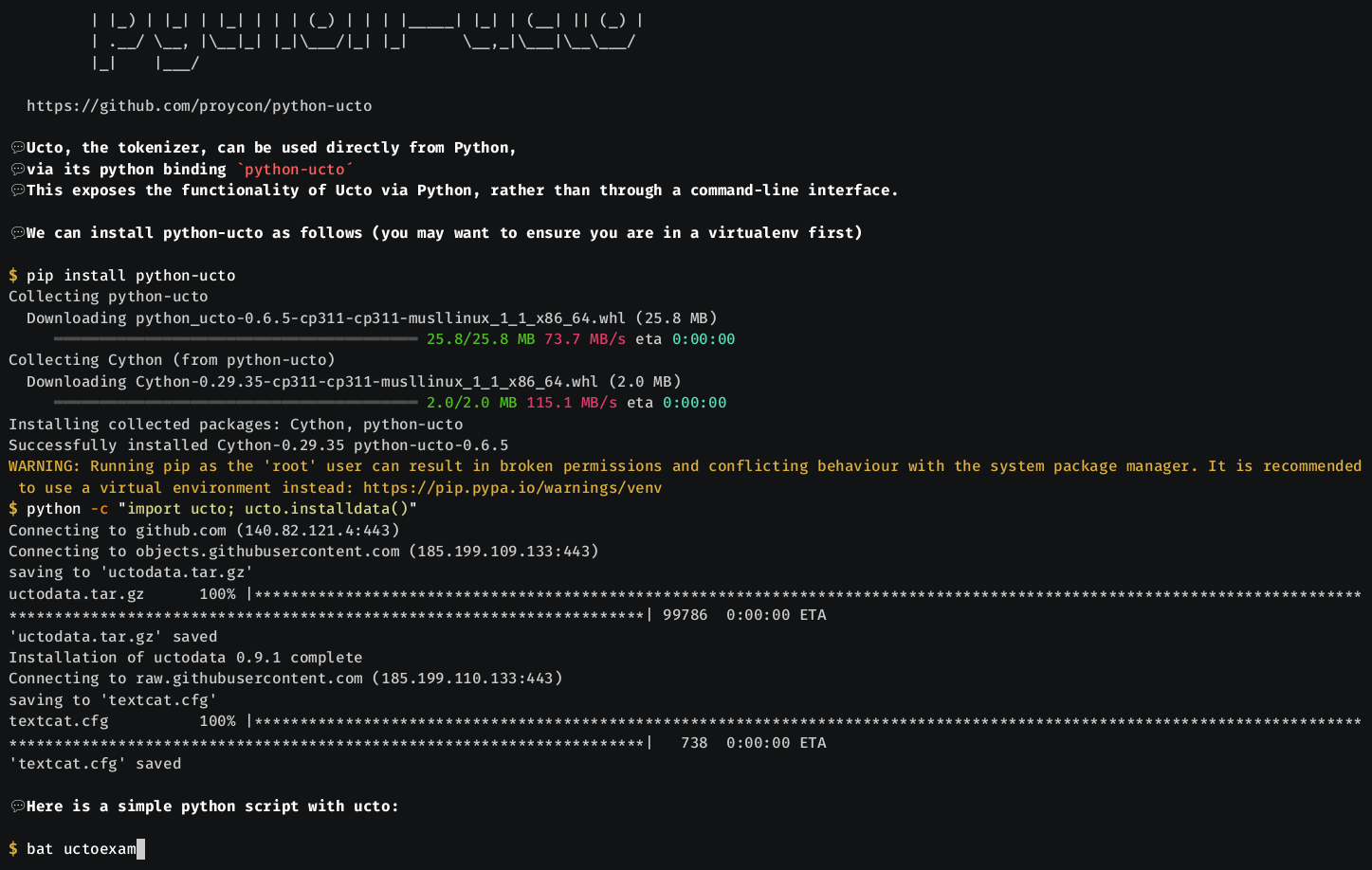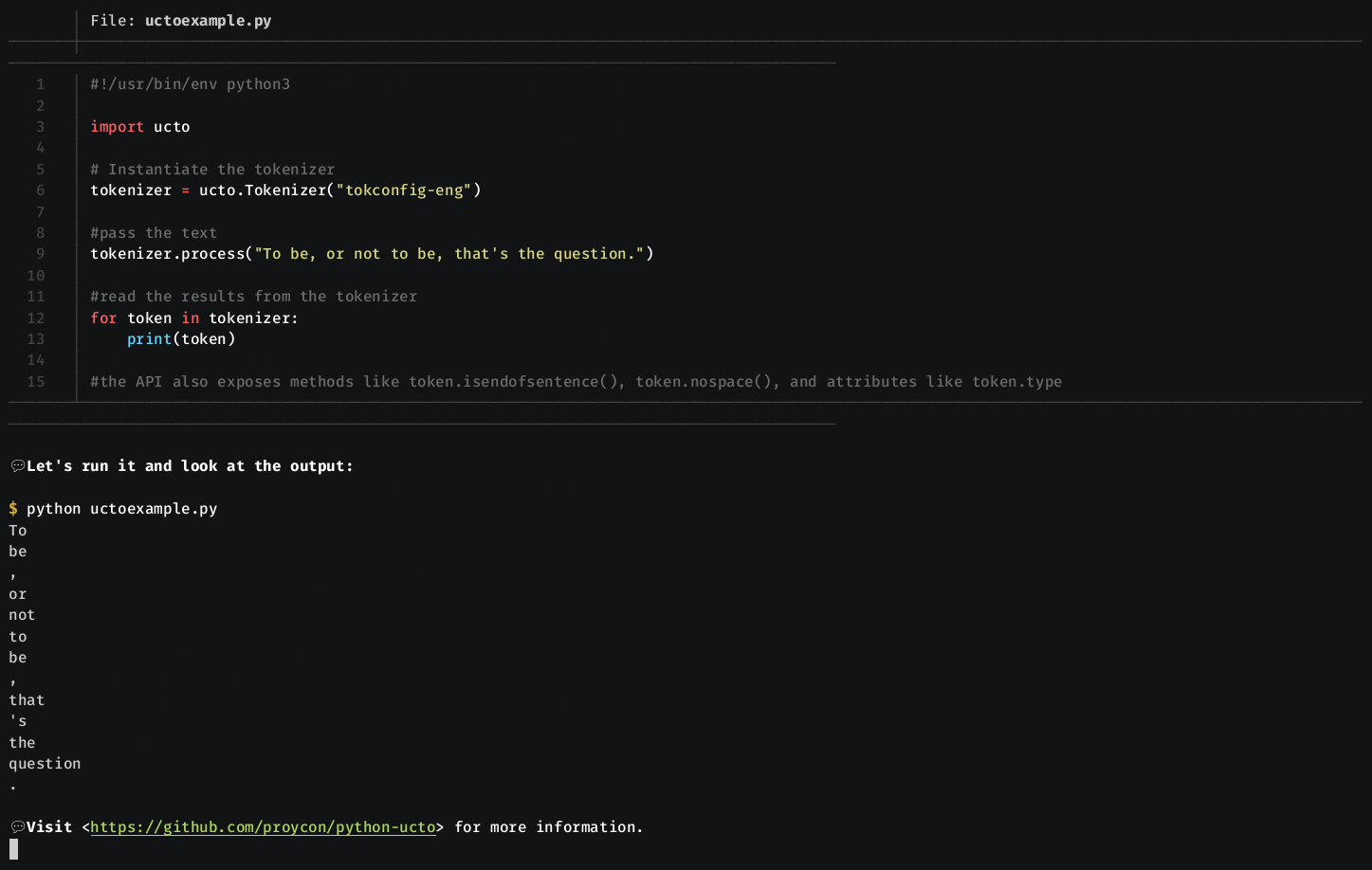
Ucto can be used from Python through the python-ucto binding, which can be downloaded and installed with pip install python-ucto.
Demo