Towards more variation in text generation:
Developing and evaluating variation models for choice of referential form
Thiago Castro Ferreira
Emiel Krahmer
Sander Wubben
Automatic Text Generation
Extracted from Narrative ScienceSystems vs. Journalists
(Clerwall, 2014)Systems-generated texts are more...
...descriptive, informative, trustworthy, objective...
...boring and unpleasant to read!
Why boring and unpleasant to read?
Determinism
Always the same output for the same input
Lack of variation
Same style and kind of text
Referring expression generation (REG)
Crucial for the coherence of the produced textVaried references without negatively affect the coherence and comprehensibility of texts
Choice of Referential Form
First decision of REG models
-
... proper name?
- Benner went 2-3, drove in one and scored one run.
-
... pronoun?
- He went 2-3, drove in one and scored one run.
-
... description?
- The player went 2-3, drove in one and scored one run.
-
... demonstrative?
- This player went 2-3, drove in one and scored one run.
-
... empty?
- Benner went 2-3, _ drove in one and _ scored one run.
Models for choice of referential form
(Reiter and Dale, 2000; Henschel et al., 2000; Callaway and Lester, 2002; Gupta and Bandopadhyay, 2009; Greenbacker and McCoy, 2009)
All are deterministic
Limitation
Models are evaluated against corpus with only one gold standard
Corpus vs. Model
-
Corpus:
- Benner went 2-3, drove in one and scored one run.
-
Model for Choice of referential form:
- The player went 2-3, drove in one and scored one run.
The use of a proper name does not necessarily mean that the use of a description is wrong.
Corpus vs. Model
-
Corpus:
- Writer 1: Benner went 2-3, drove in one and scored one run.
- Writer 2: ???
- Writer 3: ???
- ...
... humans (presumably) are not deterministic
Solution
VaREG corpus
(Ferreira et al., 2016)
More than one referring expression per situation
VaREG corpus
36 texts
12 news texts, 12 product reviews and 12 encyclopedic texts
78 participants
~ 20 per text
9588 referring expressions in 563 referential gaps
Annotated according to 5 referential forms
Writers' choices variation
Quantified in each gap by the normalized entropy measure$H(X) = - \sum\limits_{i = 1}^{n = 5} \frac{p(x_{i}) \log (p(x_{i}))}{\log (n)}$
where $n$ is the number of referential forms
ranging from 0 (no variation) to 1 (full variation)
Genre
Syntactic Position
Subject referents vs. Object referentsReferential Status
New referents vs. Old referentsRecency
Close to their previous mention vs. Distant to their previous mentionCorpus vs. Model
-
Corpus:
- Writer 1: Benner went 2-3, drove in one and scored one run.
- Writer 2: Benner ...
- Writer 3: The player ...
- ...
-
Model for choice of referential form:
- ??? went 2-3, drove in one and scored one run.
Modeling
Reference $\Rightarrow (X, y)$
$X \Rightarrow$ set of discourse features
$y \Rightarrow$ referential form distribution among referential forms
Discourse Features
Syntactic position
Subject, object or a genitive noun phrase in the sentence.
Referential Status
First mention to the referent (new) or not (old) at the level of text, paragraph and sentence.
Recency Distance between a given reference and the last, previous reference to the same referent.
Distribution over referential forms
$y = \begin{bmatrix} PN = 0.6 \\ P = 0.2 \\ D = 0.15 \\ Dem = 0.05 \\ E = 0 \ \end{bmatrix}$Proper names ($PN$), pronouns ($P$), descriptions ($D$), demontratives ($Dem$) and empty references ($E$)
Naive Bayes
$P(f \mid X) \propto \frac{P(f) \prod\limits_{x \in X} P(x \mid f)}{\sum\limits_{f' \in F} P(f') \prod\limits_{x \in X} P(x \mid f')}$
additive smoothing with $\alpha = 2e^{-308}$
Naive Bayes
$\hat{y} = \begin{bmatrix} P(PN \mid X) \\ P(P \mid X) \\ P(D \mid X) \\ P(Dem \mid X) \\ P(E \mid X) \end{bmatrix}$
A referential form is chosen based on previous choices to the same referent (Chafe, 1994; Arnold, 2008).
$P(y_{t} \mid X_{1}, ..., X_{t}, y_{1}, ..., y_{t-1})$
Recurrent Neural Network
Given a reference $X_{t}$ and a context window size $win$...
$e_{t} = (X_{t-win/2}^{t-1}; X_{t}; X_{t+1}^{t+win/2})$
$h_{t} = sigmoid(W^{he} e_{t} + W^{hh} h_{t-1})$
$\hat{y_{t}} = softmax(W^{yh} h_{t})$
| Training Method | BPTT |
| Cost Function | Cross entropy |
| Batch Size | 10 |
| Context Window Size | 3 |
| Epochs | 15 |
| Embedding Dimension | 50 |
| Hidden Layer Size | 50 |
| Learning Rate | 0.1 |
Individual Variation Experiment
Training and testing on VaREG corpus
Cross-validation
Metrics
$JSD(y || \hat{y})$: Jensen-Shannon divergence
Ranges from 0 (full convergence) to 1 (full divergence).
$\rho_{y, \hat{y}}$: Spearman's rank correlation coefficient
Ranges from -1 (opposite direction) to 1 (similar direction), with 0 indicating a non-correlation.
Baselines
$Random$
$\hat{y}$ as a random distribution over the forms
$ParagraphStatus$
$
\hat{y} = \begin{cases}
\begin{bmatrix} PN = 1 & P = 0 & D = 0 & Dem = 0 & E = 0 \end{bmatrix}, & \text{if new topic} \\
\begin{bmatrix} PN = 0 & P = 1 & D = 0 & Dem = 0 & E = 0 \end{bmatrix}, & \text{otherwise}
\end{cases}
$
Training and testing on VaREG corpus
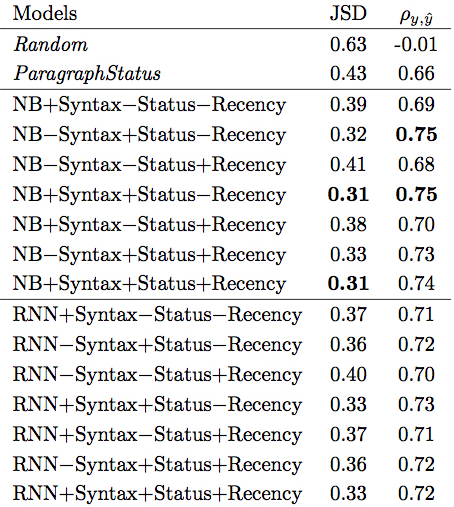
Features
To model individual variation...
Referential status features were the most helpul
Syntactic position helps
Recency did not help!
Better to measure recency by number of competitors between two references to the same referent.
Naive Bayes vs. RNNs
Naive Bayes outperforms RNNs in this particular task
Possible Reasons
VaREG is a small dataset.
Although the complexity of our problem is also small.
Referential status features are enough to model the relation among a reference and its antecedents.
Coherence and Comprehensibility
Are the texts generated by our method coherent and comprehensible?
Materials
NB+Syntax+Status-Recency
Trained on VaREG corpus
Best model in previous experiments
9 texts
Randomly extracted from GREC-2.0
Text Versions
Original
Original references to the topic
Random
Random references to the topic
Generated
References to the topic regenerated by our model
Generated
Given a text...
Group all references by $X$
#Features: Syntactic position and Referential status
For each group...
Apply $\hat{y}$
#Model: NB+Syntax+Status-Recency trained on VaREG corpus
Experiment
3 lists of texts
9 texts per list
3 Original, 3 Generated and 3 Random
30 participants
10 per list
Goal: Evaluate coherence and comprehensibility
In a scale from 1 (very bad) to 5 (very good)
Link
Coherence
Comprehensibility
In sum...
Original are more coherent and comprehensible than Random.
Generated are more coherent than Random.
No difference among Original and Generated.
Conclusions
Individual variation modeling
Without negatively affecting the quality of the texts
A step towards less boring generated texts